ai_versus
Game Screen
- Deep Q Network has not applyed yet.
Background / Status
- Motivation
- To continue studying AI technics, I think it's good to make game by myself, and apply AI to the game.
- Goal
- AI will exceeds humans, on my hand-made game.
- Progress
- Finished making game which is equal among CPU(to be AI) and player(human).
- CPU is cotrolled by rule-based routine for now.
- Now on phase of designing and applying Deep Q Network on the game.
Game Rules
- If the base destroyed, CPU/Player lose.
- If the leader destroyed, it takes time to respawn at the base.
- Conditions are equal among CPU and Player side.
- Both CPU and Player leader is controllable by AI, in future.
- Also plan to set AI to both side. (AI versus AI)
Planes
| Name | CPU | Player | Notes |
|---|---|---|---|
| leader |  |
 |
Move to free direction. Shoot to free direction. Controlled by CPU, or by player with joypad. |
| base |  |
 |
Do not move, intercept shoot and have barrior around the base. Destroyed to LOSE. |
| warship |  |
 |
High HP, slow speed. Controlled by random and heatmap based. |
| fighter |  |
 |
Low HP, normal speed. Controlled by a lesser rule-based routine, and heatmap based. |
Deep Q Network design. (Now on consideration.)
-
Basic theory to apply DQN, my understanding.
- Action : Newral network output is variables of action of leader.
- State : Newral network input is variables of environment state.
- Reward : Reward for Q update is by calcurated by rule-base, for 1st version.
- Ideal goal is not to this, just feed whole frame to CNN, maybe.
-
Action, of leader.
- Movement
- It is 360 degree free, by joystick.
- I will discretize it to..
- 8 directions, step by 45 degree.
- or 12 directions, step by 30 degree.
- Shooting
- Same as movement.
- Movement
-
State
- For state, plan to use heat-map as input.

- Small figure(upper) shows each plane positions as mini-map.
- Lower one is a heat-map.
- CPU(AI) colored red, Player colored green, graded by their HP.
- For state, plan to use heat-map as input.
-
Reward
- This shooter game has many environment variables, so I would like to determine the state, and related rewards for 1st version.
- It may be better to use clipping for rewards, that mean reward to be [-1, 0, 1].
-
In addition to the table below, a human player can watch minimap and notice-window. But It may be difficult to describe them as rewards, so exclude them on 1st version.
-
Currently 6 rewards are planned, so total reward is to be calculated as \(\sum_i(w_i*x_i)\).
- This shooter game has many environment variables, so I would like to determine the state, and related rewards for 1st version.
| No | Environment State | Rewards | Hypothesis |
|---|---|---|---|
| 1 | Total HP of planes on the ~~game view area.~~ global area. | Ratio among CPU/Player, converted to be -1 <= x <= 1 |
~~It is better to be dense as army in the view area.~~ That's a human sence and not so good to give that kind of. Alternatively use total HP. |
| 2 | HP of leaders. | Ratio among CPU/Player, converted to be -1 <= x <= 1 |
The leaders are the most important for this battle, so this must be watched. |
| 3 | HP of bases. | Ratio among CPU/Player, converted to be -1 <= x <= 1 |
The bases are also important same as leaders. |
| 4 | Shotplus timer of leaders. | Ratio among CPU/Player, converted to be -1 <= x <= 1 |
This is strengthened state of leaders, which shoot 4 bullets at the same time. So this states is also important. |
| 5 | Distance to the items, by leaders. | Ratio among CPU/Player, converted to be -1 <= x <= 1 |
3 items are there, HP+ / shotplus(timer) / warship call. AI may decide to get item, for this state and rewards. |
| 6 | Distance to the enemy base, by leaders. | Ratio among CPU/Player, converted to be -1 <= x <= 1 |
The goal is to destroy the base. AI may decide to be closer to enemy's base. |
-
Class design
-
Plan to add agent_brain module for replacing AI handler from random rule-based logics to DQN.
-
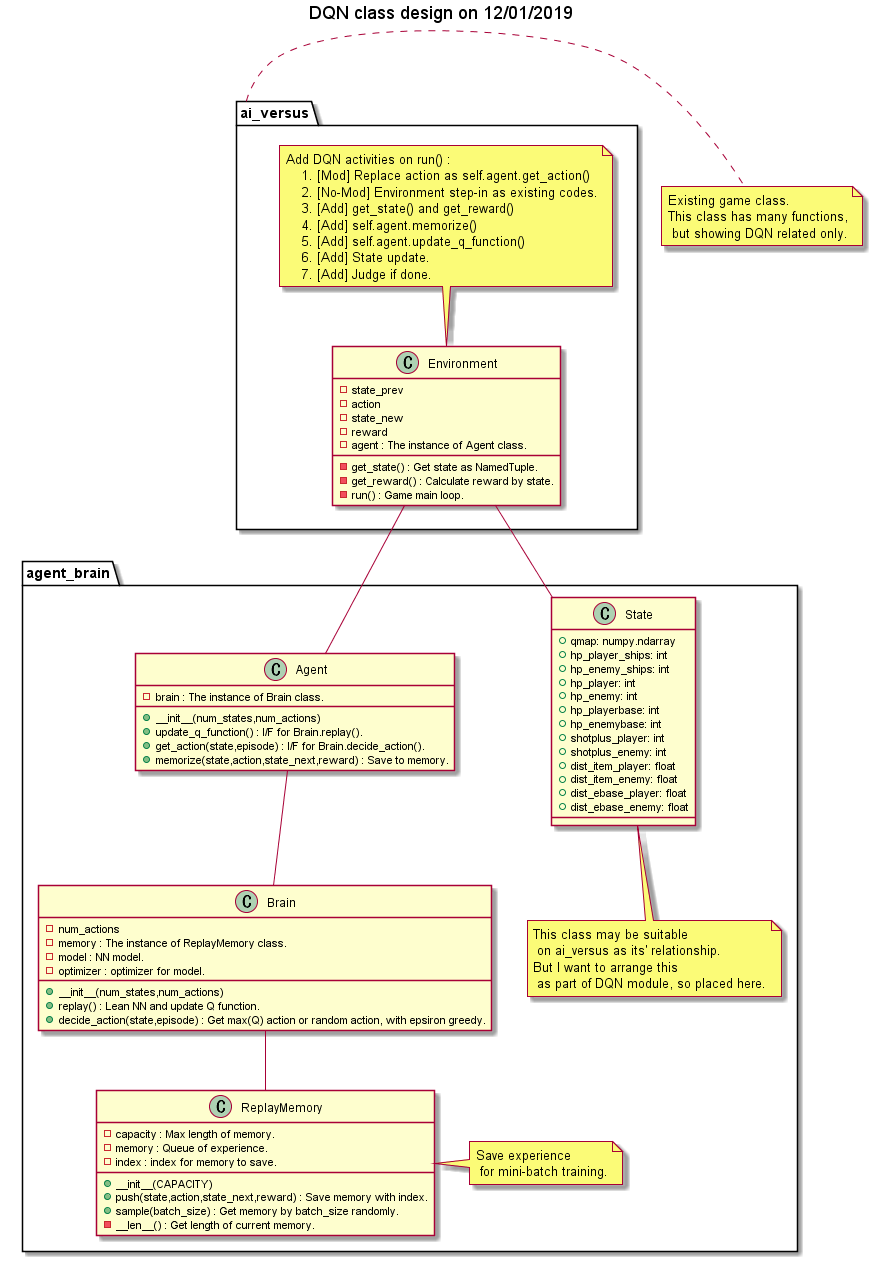
-
DQN Results
- Continued after implementation.